들어가기
Repository를 사용해 쿼리 메소드로 어느정도 데이터 처리하는데 문제는 없지만 정교하고 복잡한 처리를 할 경우 한계가 있다. 이런 한계를 JPQL을 사용해서 다양한 쿼리를 실행할 수 있다. Spring Data에서 @Query을 사용해서 쉽게 JPQL을 사용할 수 있도록 만들어준다. 사전에 Ansi SQL 학습을 권장한다.
작성자: http://ospace.tistory.com/ (ospace114@empal.com)
환경 구성
앞으로 사용할 엔티티는 총 3개로 아래와 같이 구성된다.
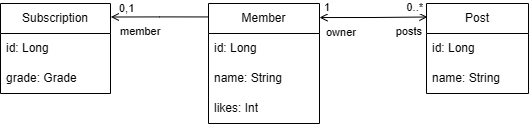
아래는 데이터베이스에서 사용할 초기 데이터이다.
insert into member(name, likes) values ('bar', 1);
insert into member(name, likes) values ('fox', 1);
insert into member(name, likes) values ('foo', 3);
insert into subscription(member_id, grade) values (1, 'PREMIUM');
insert into subscription(member_id, grade) values (2, 'FREE');
insert into subscription(member_id, grade) values (3, 'FREE');
insert into post(name, owner_id) values ('jpa', 1);
insert into post(name, owner_id) values ('spring data', 1);
insert into post(name, owner_id) values ('kotlin', 2);
insert into post(name, owner_id) values ('jpa', 3);@Query 어노테이션
@Query 어노테이션은 리포지토리에서 사용하며 JPQL을 쉽게 사용할 수 있도록 만들어준다. JPQL을 들어가기 전에 @Query을 다루는 이유는 JPQL 쿼리를 실행하기 위해서이다. 간단하게 @Query 사용법을 살펴보자. 예를 들어 다음 같은 리포지토리가 있다고 하자.
interface MemberRepository : Repository<Member, Long> {
fun findAll(): List<Member>
}Member 엔티티를 다루기 위한 리포지토리이다. findAll()은 모든 멤버에 대한 정보를 가져올 수 있는 쿼리 메소드이다. 이를 @Query 어노테이션에서 JPQL 쿼리 형태로 메소드 위에서 사용하다. 앞의 예를 사용하면 다음과 같다.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT m FROM Member m")
fun getMembers(): List<Member>
}만약 데이터베이스 방언으로된 네이티브 SQL쿼리를 사용하고 싶다면 nativeQuery 속성을 true로 설정해주면 된다.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT * FROM member m", nativeQuery=true)
fun getMembers(): List<Member>
}일반적인 데이터베이스에 실행되는 SQL 쿼리이다. nativeQuery 사용은 특정 데이터베이스에 종속될 수 있기에 추천하지 않는다.
만약 인자로 값을 이름으로 JPQL에 파라이터 바인딩을 하려면 콜론(:)을 사용해서 표현할 수 있다.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT m FROM Member m WHERE m.id = :id")
fun getMember(id:Long): Optional<Member>
}“:id”형태로 인자 이름기반으로 파라미터 바인딩이 된다. 인자 위치를 사용해서 파라미터 바인딩이 가능하다. 리턴되는 형은 Optional로 되어 있다. 리턴 형이 Member으로 사용가능하다. 그러나 리턴형이 Member인 경우 리턴이 null인경우는 처리하지 못한다. Optional로 사용하면 null도 가능하다. 물론 Member? 형으로 사용하면 null도 리턴가능하다.
인자 인덱스 위치로도 사용가능하다. 위치는 물음표(?)을 사용해서 표현된다. 경우는 예를 보자.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT m FROM Member m WHERE m.id = ?1")
fun getMember(id:Long): Member?
}위치 파라미터 바인딩의 표현은 “?인덱스번호” 형태로 된다. 인덱스 번호는 1부터 시작한다. 인젝스 번호보다는 이름기반 파라미터 바인딩이 유지보수나 실수를 방지할 수 있어 권장한다. 리턴형으로는 Member?을 사용했다.
만약 JPQL과 Spring Data로 정렬을 처리하려면 어떻게 할까?
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT m FROM Member m")
fun getMembers(sort: Sort): List<Member>
}간단하게 Sort 인자를 넘겨줘서 같이 처리할 수 있다. 단 nativeQuery를 사용할 경우는 안된다. 만약 페이징 처리는 어떻게 될까? Sort와 마찬가지로 처리할 수 있다.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT m FROM Member m")
fun getMembers(pageable: Pageable): List<Member>
}JPQL과 페이징 처리는 nativeQuery에서도 사용 가능하다.
@Query은 조회 쿼리에서 사용할수 있는데, 만약 수정과 추가 쿼리는 어떻게할까? 그냥 사용하면 되지 않을 까하지만 @Modifying 어노테이션을 같이 사용해야 한다.
interface MemberRepository : Repository<Member, Long> {
@Modifying
@Query("UPDATE Member m SET u.name = :name WHERE m.id = :id")
fun getMemberName(@Param("name") name:String, @Param("id") id:Long)
}@Param 어노테이션으로 이름 기반 파라미터 바인딩에 사용할 인자 이름을 지정할 수 있다. 이는 nativeQuery인 경우에도 동일하다. JPQL 쿼리의 상세한 부분은 아래에서 다룰 예정이다.
앞에서 간단한 맛보기로 JPQL을 사용했다. 그냥 보기에는 SQL처럼 보이지만 SQL은 아니다. 이제 부 터 JPQL을 자세히 살펴보자.
JPQL
JPQL(Java Persistence Query Language)로 JPA에서 사용하는 객체지향 쿼리 언어로 엔티티를 처리할 수 있는 쿼리이다. Ansi SQL과 형태는 비슷하지만 상세한 부분에서 차이가 있다. 특정 데이터베이스에 의존하지 않으며 런타임에 데이터베이스 방언으로 해석되서 실행된다. 즉, JPQL은 특정 데이터베이스 쿼리에 종속되지 않고 데이터베이스에 맞게 변환된다. 그래서 쿼리라고 데이터베이스에 실행하는 로우레벨 쿼리라고 생각하면 안된다. 어떻게 보면 엔티티에 대한 쿼리라고 볼 수 있다. 기본적인 구조를 살펴보자.
jpql_query ::= select_statement | update_statement | delete_statementJPQL 문은 select, update, delete 문 중에 하나를 선택할 수 있다.
Select 문
먼저 select 문은 다음과 같은 구조로 되어있다.
SELECT select_exp {, select_exp}*
FROM entity_name AS alias
[WHERE conditional_exp]
[GROUP BY group_exp]
[HAVING conditional_exp]
[ORDER BY order_item]FROM는 조회할 대상을 지정하는데 엔티티 이름(entity_name)과 별칭(alias)은 필수로 사용해야 한다.또한 AS는 생략할 수 있다. 쿼리에서는 앞으로 alias를 사용한다. Select문의 선택식(select_exp)에서도 alias를 사용해 엔티티 전체 또는 엔티티 내의 속성을 지정할 수 있다. 그리고, 이후에 조건문(WHERE), 집합절(GROUP BY), 정렬(ORDER BY) 구문이 온다. 대괄호 표기는 선택적으로 사용한다는 의미이다.
Select 문 사용하는 예를 보자.
SELECT m FROM Member AS m WHERE m.name='foo'FROM 절에 의해 가져올 대상이 Member 엔티티이고 별칭을 m을 사용했다. 그리고 WHERE 조건절에 의해 별칭 m에서 name이라는 속성이 ‘foo’ 문자열과 동일한 Member을 추출하고 별칭 m인 엔티티의 모든 값을 가져돈다. WHERE은 조건에 맞는 데이터를 검색한다. WHERE의 자세한 내용은 아래에서 다룰 예정이다.
주의할 부분은 FROM에 엔티티 이름이나 필드 이름에는 대소문자를 구분한다. 나머지 키워드는 대소문자를 구분하지 않는다. 앞에 쿼리를 @Query 어노테이션을 사용해서 정의해보자.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT m FROM Member AS m WHERE m.name='foo'")
fun getMember(id: Long): Member?
}쿼리가 @Query에 포함되었다. 리턴형이 Member?으로 되어 있다. select_exp이 Member의 별칭인 m을 사용했으므로 Member 엔티티로 매핑될 수 있다. 만약 멤버의 이름만 가져오고 싶다면 “m.name” 형태로 별칭과 속성으로 표현하면 된다. 이때에서는 가져온 속성 타입인 문자열을 리턴 타입으로 하면 된다.
여러개 선택할 대상을 조회하고 여러개 엔티티를 가져올려면 콤마(,)로 구분해서 표현할 수 있다
SELECT m, p FROM Member AS m, Post AS pselect_exp에서 DISTINCT나 AVG(), MAX(), MIN(), SUM(), COUNT() 도 사용가능하다. 자세한 설명은 아래 함수 항목을 참조하기 바란다.
간단한 사용 예를 보자.
SELECT COUNT(DISTINCT m.name) FROM Member AS mDISTINCT는 m.name으로 멤버의 이름 앞에 사용해서 중복을 제거한다. 또한 COUNT()로 데이터 개수 가져온다. 즉, 중복을 제거한 개수를 계산한다. 위의 쿼리 결과는 정수형으로 리턴된다. 참고로 COUNT()에서 null 값은 무시되고, 값이 없는데 사용할 경우 결과는 null이 된다. 아래는 리포지토리에서 @Query 어노테이션 사용 예이다.
interface MemberRepository : Repository<Member, Long> {
@Query("SELECT COUNT(DISTINCT m.name) FROM Member m'")
fun countOfMember(): Int
}결과가 정수이기 때문에 리턴형은 Int 형으로 사용했다.
GROUP BY, HAVING
다음은 GROUP BY, HAVING은 특정 그룹으로 묶어서 데이터를 추출할 때 사용한다.
GROUP BY group_exp{, group_exp}*
[HAVING conditional_exp]그룹 표현식(group_exp)은 엔티티의 속성을 지정하면 된다. 중괄호 범위가 반복되서 나오는 형태로 콤마(,)로 구분되서 여러개 group_exp을 사용할 수 있다. HAVING의 조건식(conditional_exp)은 추출을 원하는 조건을 입력하면 된다. HAVING은 조건에 만족하는 경우만 포함된다. 이는 WHERE와 동일한 conditional_exp로 아래 WHERE 항목을 참조하기 바란다.
간단한 사용 예를 보자.
SELECT
m.subscription.grade AS grade,
COUNT(m.name) AS cnt,
MAX(m.likes) AS max_likes,
AVG(m.likes) AS avg_likes,
MIN(m.likes) AS min_likes
FROM Member m
GROUP BY m.subscription.grade
HAVING MIN(m.points) > 0SELECT의 select_exp에서 AS를 사용해 별칭을 부여할 수 있다. 이런 쿼리 결과는 리포지토리에서 어떻게 가져올까? 가장 쉬운 방법은 Map을 사용한 방법이다.
interface MemberRepository : Repository<Member, Long> {
@Query("""
SELECT
m.subscription.grade AS grade,
COUNT(m.name) AS cnt,
MAX(m.likes) AS max_likes,
AVG(m.likes) AS avg_likes,
MIN(m.likes) AS min_likes
FROM Member m
GROUP BY m.subscription.grade""")
fun statOfMember(): List<Map<String, String>>
}키값 형태의 맵객체에 별칭으로 저장된다. 그리고 List형태로 리턴된다.
NEW
Map 객체를 사용해서 결과를 리턴하기 보다 VO나 DTO 사용을 권장한다. 이때 NEW 키워드를 사용해 클래스 생성자 호출해서 값을 초기화할 수 있다. 먼저 데이터를 저장할 VO 클래스를 정의해보자.
data class MemberGradeStatVo(
val grade: Grade,
val cnt: Long,
val maxLikes: Int,
val avgLikes: Double,
val minLikes: Int,
)정의한 VO 클래스를 사용해보자.
interface MemberRepository : Repository<Member, Long> {
@Query("""
SELECT NEW com.tistory.ospace.member.entity.MemberGradeStatVo(
m.subscription.grade,
COUNT(m.name),
MAX(m.likes),
AVG(m.likes),
MIN(m.likes)
) FROM Member m
GROUP BY m.subscription.grade""")
fun statOfMember(): List<MemberGradeStatVo>
}조회한 값에 alias로 별칭을 부여할 필요는 없다. NEW로 클래스 인스탄스하면서 생성자에 조회한 값을 넘긴다. 클래스 명시할 때에는 완전한 패키지 경로를 지정해야 한다. 그렇지 않으면 해당 클래스를 찾지 못한다. 만약 엔티티를 직접 사용할 경우에는 클래스 이름만 지정해도 인식한다.
org.springframework.dao.InvalidDataAccessApiUsageException: Cannot instantiate class 'com.tistory.ospace.member.entity.MemberStatVo' (it has no constructor with signature [com.tistory.ospace.member.entity.Grade, java.lang.Long, java.lang.Integer, java.lang.Double, java.lang.Integer], and not every argument has an alias)한가지 주의할 부분은 가져온 데이터 타입을 주의해야 한다. Subscription 엔티티에서 grade 필드 타입이 열거형 Grade이다. 그리고 COUNT()은 Long, MAX()은 Int, MIN()은 Int, AVG()은 Double 형이다. Int은 Long으로 사용해도 돼기 때문에 앞에 MemberStatVo 클래스의 필드 타입처럼 지정해도 된다. 만약 이 타입도 같지 않다면 타입이 틀렸다고 하면서 아래와 같은 예외가 발생하여 인스탄스되지 않는다.
org.springframework.orm.jpa.JpaSystemException: Error instantiating class 'com.tistory.ospace.member.entity.MemberStatVo'ORDER BY
ORDER BY는 Select 문에서 조회한 데이터의 정렬 방식을 지정할 수 있다.
ORDER BY order_item {, order_item}*ORDER BY에서 order_item은 엔티티 속성과 정렬 조건을 선택하면 된다. 콤마로 여러 정렬 조건을 입력할 수 있다. order_item는 다음과 같은 형식을 가진다.
order_item ::= alias.field_name [ASC|DESC]order_item은 엔티티의 필드를 지정하고 정렬 방식인 ASC(오름차순) 또는 DESC(내림차순)을 지정한다. 만약 정렬 방식을 지정하지 않으면 기본으로 ASC가 적용된다.
SELECT m FROM Member m ORDER BY m.name ASC, m.likes DESCJOIN
조인은 Select 요청에서 연관 관계가 있는 두 엔티티 간에 데이터를 합쳐서 가져오는 기능이다.
[LEFT [OUTER] | INNER] JOIN join_expSQL 조인은 ON을 이용해 연결점을 만들지만 이미 연관관계가 있기 때문에 연관 필드를 지정해서 조인하는 형태로 서로 조금 다르다. join_exp에서 조인 대상의 연관관계가 있는 속성을 지정한다. 그러면 알아서 연관관계 정보를 사용해서 조인을 실행한다. 조인 종류로 내부 조인, 외부 조인, 컬랙션 조인, 페치 조인이 있다. 하나씩 살펴보자.
내부 조인
내부 조인은 INNER JOIN으로 두 대상 간에 공통된 부분만 추출한다. 집합에서 교집합이라고 할 수 있다. INNER는 생략할 수 있다.
SELECT m FROM Member m JOIN m.subscription s WHERE s.grade = 'FREE'Member 엔티티의 연관 관계가 있는 subscription을 지정했다. 이미 Member 엔티티는 Subscription 엔티티와 연관 관계가 있어서 여기서는 내부 조인으로 지정했다.
외부 조인
외부 조인은 LEFT OUTER JOIN으로 왼쪽 엔티티를 모두 가져오고 이를 기준으로 대상 엔티티에서 데이터를 가져온다. OUTER는 생략 가능하다.
SELECT m FROM Member m LEFT JOIN m.subscriptionMember 엔티티의 연관 관계가 있는 subscription 속성을 외부 조인으로 지정해서 사용하고 있다. 만약 Member 중에 Subscription 관계가 없어도 포함된다.
페치 조인
페치 조인은 성능 향상을 위한 기능이다. 연관 엔티티나 컬랙션을 한번에 가져오는 기능으로 LAZY에 의해 지연 로딩이 되어 있었도 한번 조회로 모두 가져온다. 기존 조인에 의한 데이터 로딩은 연관 엔티티를 로딩하기 위해서 쿼리를 한번 더 실행하지만, 페치 조인은 한번 쿼리로 가져오기 때문에 성능상 이점이 있다.
[ LEFT [OUTER] | INNER ] JOIN FETCH join_expression사용예를 보자.
SELECT m FROM Member m JOIN FETCH m.subscriptionMember 엔티티를 조회할 때 Subscription 엔티티도 같이 쿼리 한번에 조회한다.
페치 조인은 한번 쿼리로 모든 데이터를 가져올 수 있지만, 불필요한 엔티티를 자주 로딩하기 때문에 전체적으로 성능에 안좋을 수 있다. 최적화가 필요한 곳에만 페치 조인을 적용하게 효과적이다. 다음은 페치 조인의 단점이다.
- 페치 조인 대상에 별칭을 줄 수 없다
- 둘 이상의 컬렉션 페치를 할 수 없다.
- 컬랙션을 페치 조인하면 페이징을 사용할 수 없다.
세타 조인
WHERE 절을 사용해 세타 조인을 할 수 있다. 이때 조인은 내부 조인형태이다. 기존 조인은 연관관계가 있는 엔티티가 대상이지만 세타조인은 연관관계가 없는 엔티티 간에도 조인할 수 있다.
SELECT count(p) from Member m, Post p WHERE m = p.owner조인 표현식을 사용하지는 않고 직접 두 엔티티 Member와 Post의 속성을 비교하고 있다.
JOIN ON 조건
ON 절을 사용해 조인 대상을 필터링할 수 있다. 조인에 대한 조건절이라고 말할 수 있다.
SELECT m, p FROM Post p LEFT JOIN p.owner m ON m.name = 'foo'UPDATE와 DELETE 문
Update 문은 단일 엔티티를 갱신한다.
UPDATE entity_name AS alias SET alias.field_name = value {, alias.field_name = value}* [WHERE conditions]엡데이트할 엔티티를 entity_name을 지정하고 AS을 통해 별칭를 지정한다. AS는 생략 가능하다. 그리고 SET뒤에 별f칭과 갱신할 필드 이름을 지정하고 새로운 값을 할당한다. 그리고 이를 여러 개를 나열 할 수 있다. 또한 특정 데이터만 지정하고 싶다면 WHERE을 사용해 특정 조건에 맞는 데이터만 갱신한다. 사용 예를 보자.
UPDATE Member m SET m.name='bar' WHERE m.id = 1Delete 문은 엔티티를 삭제한다.
DELETE FROM entity_name AS alias WHERE conditions삭제할 엔티티를 DELETE FROM 뒤에서 지정하고 AS로 별칭을 지정한다. Delete 문에서도 WHERE을 통해서 삭제할 대상을 conditions 조건으로 설정한다.
DELETE FROM Member m WHERE m.id = 1Update 문이나 Delete 문에 사용하는 WHERE 조건은 Select 문에 사용한 WHERE 조건과 동일하다.
WHERE 문
WHERE 문은 조건 결과가 TRUE인 경우에 데이터에 대해서 처리된다. 즉, Select 문은 조건 결과가 TRUE인 데이터만 조회되고 Update문은 조건 결과가 TRUE인 데이터만 변경되고 Delete 문은 조건 결과가 TRUE 경우만 삭제된다.
WHERE [NOT] conditional_exp {, OR conditional_exp |, AND conditional_exp }*WHERE에서 conditional_exp 조건식이 OR와 AND로 여러 조건들을 합친다. OR은 조건식 하나라도 TRUE이면 결과가 TRUE가 되고 AND는 모든 조건식이 TRUE이어야 결과가 TRUE가 된다. NOT은 결과가 반대가 된다. 또한 이런 조건을 괄호를 사용해서 비교 우선순위를 제어할 수 있다. 즉, 괄호안에 조건이 우선순위가 높다.
조건식 conditional_exp에서 사용할 수 있는 비교 연산자 comp_op를 통해서 값을 비교 할 수 있다.
alias.field_name comp_op value별칭과 엔티티의 필드 이름과 값을 비교하는 비교 연산자인 =, >, >=, <, <=, <>으로 표현할 수 있다. 값으로는 문자열, 숫자, 파라미터 바인딩, 인덱스 바인딩, 서브쿼리을 사용할 수 있다. 서브쿼리에 대한 자세한 내용은 서브 쿼리 항목을 참고하기 바란다.
비교 연산자외에 다양한 표현식인 숫자, 문자열, BETWEEN, IN, LIKE, IS NULL, IS EMPTY, MEMBER [OF], EXISTS를 사용할 수 있다. 이런 표현식은 아래 표현식 항목을 참고하시기 바란다.
서브 쿼리
JPQL에서 서브쿼리를 사용할 수 있지만 제약사항이 있다. WHERE, HAVING 구문에서만 사용할 수 있고 SELECT, FROM 구문에서는 사용할 수 없다. 그리고, 서브쿼리는 괄호로 감싼다.
SELECT m FROM Member m WHERE m.likes > (SELECT AVG(m1.likes) FROM Member m1)이 쿼리는 좋아요 횟수 평균보다 많은 회원을 조회한다. 서브쿼리에 같이 사용할 수 있는 표현식이 있다.
- [NOT] EXISTS (서브 쿼리): 서브쿼리 결과가 하나 이상 값이면 있으면 참. NOT은 부정.
- SELECT m FROM Member m WHERE EXIST (SELECT p FROM Post p WHERE p.owner = m)
최소 게시글 하나라도 있는 멤버를 조회한다.
- SELECT m FROM Member m WHERE EXIST (SELECT p FROM Post p WHERE p.owner = m)
- {ALL | ANY | SOME} (서브쿼리): 비교 연산자와 같이 사용하며 ALL은 조건을 모두 참이면 참, ANY와 SOME은 조건 중에 하나라도 참이면 참.
- SELECT m FROM Member m WHERE m.likes > ALL(SELECT p.owner.likes FROM Post p WHERE p.owner <> m)
내가 작성하지 않은 게시글의 모든 소유자보다 좋아요 수가 가장 멤버를 조회
- SELECT m FROM Member m WHERE m.likes > ALL(SELECT p.owner.likes FROM Post p WHERE p.owner <> m)
- [NOT] IN (서브쿼리): 서브쿼리 중에 하나라도 같은게 있으면 참. NOT은 부정.
- SELECT p FROM Post p WHERE p IN (SELECT p1 FROM Post p1 JOIN t1.owner m1 WHERE AVG(m1.likes) < m1.likes)
표현식
쿼리 내에서 사용하는 표현식으로 문자열, 숫자, 날짜, 열거형, 엔티티 타입 등 다양한 형태가 있다.
- 문자열
- 문자열은 작은 따옴표로 묶인다. 문자열 내에 작은 따옴표를 표기할려면 연속으로 두번(’’)사용한다.
- 예) ‘Foo’, ‘Foo’’s’
- 숫자
- 숫자 뒤에 L은 Long형, D는 Double형, F은 Float형을 표시한다.
- 예) 100L, 0.001D, 1.01F
- 열거형
- 완전한 패키지 이름이 포함된 열거형 이름을 사용한다.
- 예) com.tistory.ospace.
조건식 중에 BETWEEN, LIKE, IN, NULL, EMPTY, MEMBER, EXISTS이 있다.
- A BETWEEN B AND C
- A가 B와 C 포함해서 B와 C 사이에 값이 있으면 참이다. B <= A AND A <= C
- 예) WHERE m.likes BETWEEN 0 AND 9
- field_exp IN ( in_item {, in_item}* | subquery )
- 엔티티 필드(field_expr)에서 in_item 아이템들 중에 하나라도 있으면 참이다. 또한 서브쿼리도 사용할 수 있다.
- 예) WHERE p.name IN (’jpa’, ‘kotlin’)
- string LIKE pattern_value [ESCAPE escape_char]
- 문자열이 pattern_value 패턴에 일치하면 참. 패턴에 “%”(0개 이상 매칭)과 “_”(1개 이상 매칭)을 사용해서 표현할 수 있다. 또한 옵션인 ESCAPE을 사용해 이스케이프 문자를 지정할 수 있다. 이스케이프 문자를 사용해 앞의 특수 문자 “%”와 “_”을 문자로 사용할 수 있게 해준다.
- 예) WHERE m.name LIKE ‘foo%’
- value IS [NOT] NULL
- NULL과 비교한다. IS [NOT] NULL은 (대상) = NULL 형태로 표현할 수 있다.
- 예) WHERE p.name IS NULL
- collection_exp IS [NOT] EMPTY
- 컬랙션(collection_exp)이 EMPTY인지 비교한다.
- 예) WHERE m.posts IS EMPTY
- entity_exp [NOT] MEMBER [OF] collection_exp
- 해당 엔티티의 값(entity_expr)이 컬랙션(collection_exp)에 포함되었는지 확인한다.
- 예) WHERE p MEMBER m.posts
이외 다양한 표현식이 있다.
- CASE 식
- 조건에 따라 분기
- 예) CASE WHEN r.grade = ‘FREE’ then ‘무료’ WHEN r.grad = ‘PREMIUM’ THEN ‘프리미엄’ ELSE ‘기타’
- 예) CASE t.grade WHEN ‘FREE’ THEN ‘무료’ WHEN ‘PREMIUM’ THEN ‘프리미엄’ ELSE ‘기타’
- COALESCE
- 인수를 차례로 조회해서 null이 아니면 리턴되고 결국 마지만 인자가 리턴
- 예) COALESCE(m.name, p.name, ‘NA’)
- NULLIF
- 값이 같으면 NULL을 반환
- 예) NULLIF(p.name, ‘NA’)
- TYPE
- 별칭의 엔티티 타입을 획득
- 예) TYPE(m) IN (Member, Post)
- TREAT
- 타입 캐스팅으로 부모 타입을 특정 자식 타입으로 변환
- 예) TREAT(m AS PremiumMember).credits
- FUNCTION
- 사용자 정의 함수 호출. 호출할 함수 이름과 인자(들)을 같이 호출.
- 예) FUNCTION(’foo_op’, m.name)
위의 모든 표현식에 들어가는 NOT는 결과가 반대가 된다.
함수
JPQL에서 지원하는 함수이다.
집합 함수
| 함수 | 리턴형 | 설명 |
|---|---|---|
| COUNT() | Long | 개수 계산 |
| AVG() | Double | 평균 계산 |
| MAX() | 필드 자료형 | 최대값 계산 |
| MIN() | 필드 자료형 | 최소값 계산 |
| SUM() | Long(정수형 필드), Double(부동소수점 필드), BigInteger(BigInterger 필드) | 합계 계산 |
문자 함수
| 함수 | 설명 | 예 |
|---|---|---|
| CONCAT(parm1, param2, …) | 문자열을 합침 | CONCAT(’Hello’, ‘ world’) |
| SUBSTRING(str, idx, len) | 문자열 일부를 추출 | SUBSTRING(’Hello world’, 7, 5) |
| TRIM([[trim_spec] [trim_char] FROM] str) | 문자열 trim_spec에서 LEADING(앞), TRAILING(뒤), BOTH(앞뒤, 기본)에서 제거할 문자(trim char, 기본 공배)를 str(문자열)에서 제거 | TRIM(’ hello ‘) |
| LOWER(str) | 소문자로 변환 | LOWER(’Hello’) |
| UPPER(str) | 대문자로 변환 | UPPER(’Hello’) |
| LENGTH(str) | 문자열 길이 | LENGTH(’Hello’) |
| LOCATE(search_str, str, [idx]) | str(문자열)에서 search_str(검색 문자열)을 idx(검색시작위치, 기본 1)에서 부터 위치 찾음 | LOCATE(’world’, ‘Hello world’) |
수학 함수
| 함수 | 설명 | 예 |
|---|---|---|
| ABS(val) | 절대값 구함 | ABS(-10) |
| SQRT(val) | 제곱근 구함 | SQRT(4) |
| MOD(val, div_val) | 나머지 구함 | MOD(5, 2) |
| SIZE(val) | 컬랙션 데이터 개수 | SIZE(m.posts) |
| INDEX(alias) | 컬팩션에서 인덱스 구함 | INDEX(m) |
날짜 함수
| 함수 | 설명 |
|---|---|
| CURRENT_DATE | 현재 날짜 |
| CURRENT_TIME | 현재 시간 |
| CURRENT_TIMESTAMP | 현재 날짜 시간 |
연산자 우선순위
연산자 우선순위로 연산자가 무엇이 먼저 연산을 하는지 우선 순위가 정해진다.
| 우선순위 | 연산자 | 설명 |
|---|---|---|
| 1 | . | 경로 탐색 연산자 |
| 2 | +, -(단항연산), *, /, +, -(사칙연산) | 산술 연산자 |
| 3 | =, >, >=, <, <=, <>, [NOT] BETWEEN, [NOT] LIKE, [NOT] IN, IS [NOT] NULL, IS [NOT] EMPTY, [NOT] MEMBER [OF] | 비교 연산자 |
| 4 | NOT, OR, AND | 논리 연산자 |
어떤 연산자 우선순위보다 괄호가 가장 먼저 처리되기 때문에 연산자가 복잡하게 표현된다면 괄호 사용을 추천한다.
마무리
지금까지 JPQL에서 간단하게 다루었다. 이외에서 다양한 표현식과 사용방법이 있다. 모두 다루기에는 내용이 너무 많아서 나름대로 정리했다. 그렇게 하면서 표현형태과 용어를 자주 변경되면서 생각보다 시간이 오래걸렸다. 내용이 너무 두서 없이 정리되고 자연스럽게 흘러가지 않고 여기저거 흩어져 있는 느낌이다. 한번더 정리가 필요한데 언제할지 모르겠다.
JPQL을 보면서 SQL과 비슷하지만 다른게 생각 보다 많았다. 결국 쿼리 오류가 발생하면서 한번더 찾아서 변경해야하는 일이 많을 것 같다. JPQL가 데이터베이스에 중립적이고 투명하기 때문에 너무 하위 기술에 종속되지 않는다는 장점이 있다. 그러나 SQL에 외에도 JPQL을 알아야하고 엔티티 관점에서 쿼리를 작성해야하는 점이 있다. 또한 JPQL의 오류는 컴파일 타임이 아니라 런타임에 알 수 있다는 단점도 있다. 그러나 기존에 SQL에 익숙하다면 다양한 형태의 데이터 처리가 가능하다는 장점이 있다.
참조
[1] 최범균, JPA 프로그래밍 입문, 가메출판사, 2017
[2] 김영한, 자바 ORM 표준 JPA 프로그래밍, 에이콘, 2015
[3] Java Persistence/JPQL BNF, https://en.wikibooks.org/wiki/Java_Persistence/JPQL_BNF
Spring Data JPA @Query, https://www.baeldung.com/spring-data-jpa-query
[4] JPQL Language Reference, https://openjpa.apache.org/builds/1.2.0/apache-openjpa-1.2.0/docs/manual/jpa_langref.html, 2024.04.23
'3.구현 > Java or Kotlin' 카테고리의 다른 글
| [kotlin] JPA 9: Spring Boot에서 엔티티 이벤트 리스너 (0) | 2024.06.06 |
|---|---|
| [kotlin] JPA 8: Spring Boot에서 엔티티 매니저와 Criteria 쿼리 (0) | 2024.05.09 |
| [kotlin] JPA 6: Spring Boot에서 Repository 활용 (2) | 2024.04.18 |
| [kotlin] JPA 5: Spring Boot에서 Entity 고급관계 (0) | 2024.04.16 |
| [kotlin] JPA 4: Spring Boot에서 Entity 연관관계 (4) | 2024.04.11 |


