들어가기
JPA에서 연관관계 말로 다양한 관계를 표현할 수 있다. 클래스 상속 관계, 내포관계, 콜렉션 데이터 표현 등 다양하다. 이번에는 이전 연관간계 외에 엔티티에서 사용되는 다양한 관계를 살펴볼려고 한다.
작성자: http://ospace.tistory.com/ (ospace114@empal.com)
어노테이션 목록
- IdClass
- EmbeddedId
- MappedSuperclass
- Inheritance
- DiscriminatorColumn
- DiscriminatorValue
- Embeddable
- Embedded
- AttributeOverride
- SecondaryTable
- ElementCollection
- CollectionTable
- PrimaryKeyJoinColumn
- ForeignKey
- Index
@IdClass 어노테이션
두 어노테이션은 복합키를 정의하는데 사용한다. 이전에는 속성 하나로 기본키를 사용했지만, 복합키는 두개 이상의 속성으로 기본키로 사용된다. 먼저 @IdClass를 살펴보자.
@IdClass로 복합키로 사용할 클래스를 지정한다. 그리고 해당 클래스는 Serializable 인터페이스를 구현해야 하고 equals()와 hashCode()을 구현해야 한다.
data class MemerId(
var id: Long? = null,
var hobbyId: Long? = null,
) : SerializableSerializable가 상속해서 데이터 클래스로 정의되었고 자동으로 equals()와 hashCode()가 구현된다. 또한 기본 생성자가 있어야 한다. 이를 Member 엔티티에 적용해보자.
@Entity
@IdClass(MemberId::class)
open class Member(
@Id
@Colunm(name = "parent_id")
private var id: Long? = null,
@Id
private var hobbyId: Long? = null,
private var name: String = "",
) {
//...
}@IdClass을 사용해 클래스 상단에 복합키를 정의하고 있다. Repository을 정의할 때 복합키를 사용한다. 이는 엔티티 추가 저장할 때 특별히 활용하지 않는다.
interface MemberRepository : JpaRepository<Member, MemberId>ID 타입파라미터가 MemberId 클래스를 사용해서 정의했다. 이를 가지고 조회하는 예를 보자.
val res = memberRepository.findById(MemberId(1,0))findById()로 조회할 때에 복합키 형태로 객체를 넘겨준다.
@EmbeddedId 어노테이션
다음으로 @EmbeddedId를 살펴보자. 이때 복합키용 클래스를 정의할 때 추가 작업이 필요하다. @EmbeddedId에서 사용하기 위해서 복합키로 사용할 클래스에 @Embeddable을 선언해야 한다.
@Embeddable
data class MemerId(val id: Long? = null, val hobbyId: Long? = null) : Serializable@IdClass는 클래스 상단에 정의했지만 @EmbeddedId는 내부 속성에 추가된다. 나머지는 @IdClass 복합키 정의할 때와 동일하다.
@Entity
open class Member(
@EmbeddedId
private var id: MemberId? = null,
private var name: String = "",
) {
//...
}Repository을 정의하는 부분도 @IdClass와 동일하다. 엔티티를 추가할 때에는 id 속성은 MemberId 객체를 생성해서 설정해줘야한다. 조회할 때에는 이전과 동일하게 식별자가 MemberId이므로 객체를 생성하고 필요한 식별자 값을 설정해서 조회한다. @IdClass와는 다른 점은 엔티티내에 직접 복합키 클래스를 내장해서 정의하고 있다는 점이다. 이는 좀더 직관적으로 인지할 수 있다는 장점이 있다.
@IdClass와 @EmbeddedId를 사용해서 식별관계와 비식별관계를 매핑하는데 사용한다. 다른 엔티티에서 ToOne 매핑관계와 @JoinColumns을 사용해 복합키와 매핑 설정을 통해 관계를 지정할 수 있다. 지정하는 방법은 간단한다. 자식 엔티티가 Hobby라고 하고 @IdClass인 경우를 보자.
// 식별관계 예
@Entity
open class Hobby(
@Id
private var id: Long? = null,
@Id
@ManyToOne
@JoinColumn(name = "member_id")
private var member: Member? = null,
//...
) {
//...
}
// 비식별관계 예
@Entity
open class Hobby(
@Id
private var id: Long? = null,
@ManyToOne
@JoinColumn(name = "member_id")
private var member: Member? = null,
//...
) {
//...
}차이는 부모 엔티티와 연관관계에 대해 @Id로 지정해주는데 있다. 지정하면 식별관계, 없으면 비식별관계가 된다.
@MappedSuperclass 어노테이션
클래스의 공통적인 속성을 합쳐서 만든 상위 클래스를 슈퍼 클래스라고 한다. 이런 형태의 클래스를 만들고 서브 클래스를 정의하는 확장 구조를 만들 수 있다. 이와 동일하게 엔티티에서도 비슷하게 만들 수 있다. 이때사용하는 어노테이션이 @MappedSuperclass로 슈퍼클래스에 해당하는 슈퍼 엔티티에 적용하고 이를 상속한 여러 엔티티를 정의할 수 있다.
먼저 공통적인 속성을 가진 BaseEntity 클래스를 정의해보자.
@MappedSuperclass
@EntityListeners(AuditingEntityListener::class)
open class BaseEntity {
@CreatedBy
@Column(updatable = false)
var createdBy: Long? = null
private set
@CreatedDate
@Column(updatable = false)
var createdAt: LocalDateTime? = null
private set
@LastModifiedBy
var modifiedBy: Long? = null
private set
@LastModifiedDate
var modifiedAt: LocalDateTime? = null
private set
}BaseEntity 클래스는 생성시간과 갱신시간 정보를 가진다. 대부분의 데이트가 가진 공통적인 속성이다. 물론 어떤 데이터는 생성만 있고 갱신은 없을 수도 없다. 그럴 경우 굳이 데이터베이스에 있을 필요가 있을까하는 생각도 들지만…
이제 BaseEntity을 활용해보자. 다음은 기존 Post 엔티티를 재정의해보겠다.
@Entity
open class Post (
@Id
@GeneratedValue
private var id: Long?,
//...
) : BaseEntity() {
//...
}이제 앞으로 BaseEntity을 상속 받으면 자동으로 기본적인 필드가 추가된다. 이제 BaseEntity을 상속받는 모든 엔티티는 데이터베이스 테이블에도 BaseEntity의 필드가 매핑된다.
@Inheritance 어노테이션
@Inheritance 어노테이션은 엔티티 클래스 상속 구조에서 사용하는 전략을 정의한다. 지원하는속성은 다음과 같다.
- strategy: 상속 구조에 사용하는 전략, 열거형 InheritanceType을 사용해서 설정
클래스 상속 구조는 복잡하다. 이를 테이블로 매핑하는 작업은 쉽지가 없다. InheritanceType에 의해 3가지 전략을 선택할 수 있다.
- SINGLE_TABLE(기본): 클래스 상속 트리 구조마다 단일 테이블로 생성
- JOINED: 슈퍼 클래스에 해당하는 공통 필드를 별도로 분리된 테이블로 서브 클래스를 매핑하는 전략
- TABLE_PER_CLASS: 실제 엔티티 클래스 별로 테이블 생성
예를 들어 다음과 같은 한개의 상속 트리가 있는 경우를 보자.

SINGLE_TABLE은 상속 트리 별로 최상위 부모 엔티티 이름을 기준으로 테이블이 생성된다. 자식 엔티티에 있는 모든 필드가 컬럼으로 추가된다. 가장 간단하고 단순하다. 필요한 것들이 한 테이블이 있으니 처리도 쉽다. 그렇기 때문에 상속 깊이가 낮고 각 클래스에 필드가 적다면 유리하다. 필드가 많고 트리가 깊은 경우는 불필요한 컬럼이 많아져서 효율적이지 않게 된다.

JOINED은 모든 엔티티가 별도 테이블로 생성되고 자식 엔티티 로딩시 부모 엔티티와 조인해서 데이터를 가져온다. 데이터베이스 정규화 관점에 보면 가장 최적의 구조이다. 그리고 모든 멤버에 대한 조회도 가능한다. 그러나 자식 엔티티 로딩할 때는 매번 조인하고, 변경이나 삭제도 많아진다.
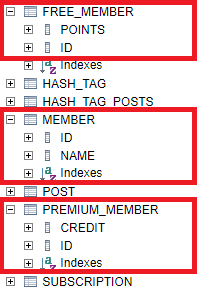
TABLE_PER_CLASS은 JOINED처럼 모든 엔티티별로 테이블이 생성된다. 차이점은 모든 필드를 자신이 가지고 있다. 데이터를 로딩할 때에 별도 조인이 필요 없다. TABLE_PER_CLASS은 SINGLE_TABLE와 JOINED의 중간적인 위치에 있다. 약간의 중복이 있지만 별도 조인이 없이 단일 테이블에서 처리할 수 있다.
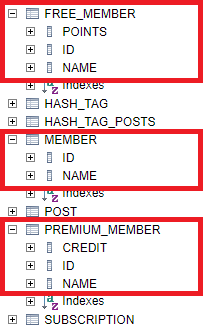
먼저 Member 부모 엔티티 클래스를 정의해보자.
@Entity
@Inheritance(strategy=InheritanceType.SINGLE_TABLE)
open class Member(
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private var id: Long?,
private var name: String?,
) {
constructor() : this(null, null) {}
open fun getId(): Long? = id
open fun setId(id:Long?) {
this.id = id
}
open fun getName(): String? = name
open fun setName(name:String?) {
this.name = name
}
}Member 클래스는 식별자와 이름을 가진 엔티티이다. 다음으로 부모 엔티티 클래스를 상속한 자식 엔티티 클래스를 정의해보자.
@Entity
open class FreeMember (
id: Long?,
name: String?,
private var points: Int,
) : Member(id, name) {
//...
}자식 엔티티 클래스에서는 단순히 상속만 해주면 된다.
@DiscriminatorColumn 어노테이션
@DiscriminatorColumn 어노테이션은 @Inheritance 어노테이션의 SINGLE_TABLE, JOINED 전략과 같이 사용되며 상속되는 하위 클래스를 판별하는 컬럼을 지정한다. @Inheritance의 SINGLE_TABLE에의해 생성된 단일 테이블을 보면 dtype 컬럼이 있다. 이 컬럼이 어떤 엔티티인지 판별하기 위한 목적이 있다. JOINED은 이미 엔티티 이름에 포함되어 있어서 별도로 없지만 부모 엔티티 테이블인 경우 각 레코드가 어떤 엔티티에 해당하는지 모르기 때문에 추가적으로 지정할 수 있다.
@DiscriminatorColumn 어노테이션에서 지원하는 속성은 다음과 같다.
- name: 클래스 판별용 컬럼 이름
- discriminatorType: 클래스 판별용 컬럼의 타입, 열거형 DiscriminatorType으로 설정
- length: 문자열 기반인 경우 컬럼 길이 설정
- columnDefinition: 컬럼 제약 조건(자세한 내용은 @Column을 참고)
열거형 DiscriminatorType은 아래와 같은 판별용 타입을 제공한다.
- CHAR: 문자 타입
- INTEGER: 정수
- STRING: 문자열
실제 사용하는 예를 보자.
@Entity
@Inheritance(strategy=InheritanceType.JOINED)
@DiscriminatorColumn(name="TYPE", discriminatorType = DiscriminatorType.STRING, length=10)
open class Member(
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private var id: Long?,
//...
) {
//...
}Member 엔티티 클래스는 JOINED으로 된 상속 매핑을 사용하고 있다. 그리고 편별용 컬럼 이름을 TYPE으로 하고 그대 컬럼 타입은 최대 10자로된 문자열을 사용하고 있다.
@DiscriminatorValue 어노테이션
판별용 컬럼에서 사용할 식별용 값을 지정한다. @DiscriminatorColumn와 같이 하위 엔티티 클래스에서 사용되며 다른 클래스와 구분하기 위한 식별 값으로 사용한다. 만약 선언하지 않으면 클래스 명이 사용된다. 보통 코드화된 값으로 엔티티를 식별하기 위해서 사용한다. 앞의 예제를 다음 처럼 정의할 수 있다.
@Entity
@Inheritance(strategy=InheritanceType.JOINED)
@DiscriminatorColumn(name="TYPE", discriminatorType = DiscriminatorType.STRING, length=2)
open class Member {
//...
}
@Entity
@DiscriminatorValue("FM")
open class FreeMember {
//...
}
@Entity
@DiscriminatorValue("PM")
open class PremiumMember {
//...
}물론 문자나 숫자로도 사용할 수 있다.
@MappedSuperclass vs. @Inheritance
두 어노테이션이 사용 용도가 비슷하다. 어느 하나만 써야하나라는 생각이 든다. 사용 용도가 엄연히 틀리다. 기반 클래스가 엔티티라면 Inheritance을 사용하지만, 그렇지 않고 공통으로 사용할 필드와 메소드를 가진 일반 클래스라면 MappedSuperclass을 사용한다. 어떻게 보면 MappedSuperclass가 믹스인(mixin) 개념과 비슷하다고 볼 수 있다.
먼저 Inheritance 예를 보자. 메시지 종류에는 SMS, email, messanger가 있고 각 개인별로 이런 메시지들을 가질 수 있다고 하자. 이럴 경우 확실하게 메시지 종류로 개별 메시지를 식별할 수 있고 메시지를 엔티티로도 정의할 수 있다. 이럴 때에 Inheritance을 사용한다.
MappedSuperclas 예를 보자. 도메인 객체마다 생성일시, 수정일시, 생성자, 수정자가 공통적으로 사용되서 이를 공통 도메인 객체로 분리할 수 있다. 이 때에는 엔티티로 정의하기 모호해서 클래스로 만들고 MappedSuperClass로 정의한다.
@Embeddable과 @Embedded 어노테이션
@Embeddable과 @Embedded 어노테이션을 사용해서 임베디드된 속성을 어떻게 다루는지 살펴보겠다. 여기서 임베디드된 속성은 소유된 엔티티에 포함되서 내제된 형태로 저장되서 사용된다. 임베디드된 속성은 엔티티 속성으로 매핑된다. 이를 @Embeddable 어노테이션으로 임베디드되는 클래스를 표현해보자.
@Embeddable
open class Address (
private var postcode: String?,
private var main: String?,
private var detail: String?,
//...
) {
//...
}정의된 임베디드 클래스를 사용해보자. @Embedded 어노테이션으로 다른 엔티티에 엠베디드되는 클래스를 필드로 사용할 수 있다.
@Entity
open class Member (
@Id
@GeneratedValue
private var id: Long?,
@Embedded
private var address: Address?,
//...
) {
//...
}Member 엔티티에 address인 주소 속성이 추가되었다. member 테이블에 주소까지 매핑된다.
@AttributeOverride 어노테이션
@AttributeOverride 어노테이션은 기존 속성 매핑 정보를 재정의하는게 사용한다. 일반적인 필드나 속성에 적용된 매핑 정보는 @Column으로 바로 적용가능하지만 MappedSuperclass나 Embeddable인 클래스인 경우는 변경을 원하는 필드는 매핑 변경이 안된다. 이때 해당 클래스에 있는 속성에 대해 컬럼을 재정의하는데 @AttributeOverride 어노테이션을 사용해서 변경할 수 있다.
@AttributeOverride 어노테이션이 지원하는 속성은 다음과 같다.
- name: 매핑이 재정의되는 속성 이름
- column: 영속성 속성으로 매핑되는 컬럼 설정, 이전에 @Column 어노테이션을 참고
예를 들어 앞의 임베디드된 Address 클래스의 필드는 이름만으로 주소인지 인지하기 어렵다. 그래서 일부 컬럼 이름 앞에 “addr”을 붙일려고 한다. 그런데 @Column으로는 할 수 없다. 이때에 @AttributeOverride을 다음처럼 사용할 수 있다.
@Entity
open class Member (
@Id
@GeneratedValue
private var id: Long?,
@Embedded
@AttributeOverride(name="address.main", column=Column(name="addrMain"))
private var address: Address?,
//...
) {
//...
}“address.main”은 닷(.)표현을 통해 address 객체 있는 main 필드를 가리키게 된다. 그리고 해당 필드에 대한 컬럼 이름을 “addrMain”으로 매핑 설정한다. 컬럼 이름은 카멜 표기를 자동으로 언더스코어 표기로 변환해준다.
그런데 Address 클래스에는 detail 필드도 매핑 설정하고 싶다면 @AttributeOverride을 중복해서 사용할 수 없고@AttributeOverrides 어노테이션을 사용해서 다중 @AttributeOverride 어노테이션을 사용할 수 있다.
@Entity
open class Member (
@Id
@GeneratedValue
private var id: Long?,
@Embedded
@AttributeOverrides(
AttributeOverride(name = "address.main", column = Column(name = "addrMain")),
AttributeOverride(name = "address.detail", column = Column(name = "addrDetail")),
)
private var address: Address?,
//...
) {
//...
}@SecondaryTable 어노테이션
어노테이션을 지정한 클래스에 대해 추가적인 테이블을 설정한다. 이렇게 다중 테이블을 사용해서 엔티티 클래스를 매핑한다. @SecondaryTable 어노테이션을 사용하지 않으면 모든 필드나 속성은 기본 테이블로 매핑된다. 또한 조인 설정을 하지 않았다면 기본키로 조인한다. @SecondaryTable 어노테이션에 제공하는 속성은 다음과 같다.
- name: 추가 테이블 이름
- pkJointColumns: 추가 테이블의 기본키 속성, PrimaryKeyJoinColumn 어노테이션으로 설정(아래 참조)
- catalog: 데이터베이스 catalog 이름
- schema: 데이터베이스 schema 이름
- foreignKey: pkJointColumns에 해당하는 컬럼에 대한 외래키 제약조건 생성 설정, ForeignKey 어노테이션으로 설정(아래 참조)
- uniqueConstraints(DDL): 유니크 제약 조건
- indexes: 테이블을 위한 인덱스, Index 어노테이션을 설정(아래 참조)
실제 사용하는 예를 보자.
@Entity
@SecondaryTable(name="memberDetail")
open class Member(
//...
@Column(table="memberDetail")
private var nickname: String?,
) {
//...
}추가되는 테이블 이름은 “memberDetail”로 지정한다. 실제 생성되는 테이블 이름은 “member_detail”이 된다. 실제 사용할 필드나 속성에 @Column의 table 속성으로 컬럼에 대해 사용할 테이블을 지정할 수 있다.
만약 추가되는 테이블이 여러 개 일 경우는 @SecondaryTables 어노테이션을 사용한다.
@Entity
@SecondaryTables(
SecondaryTable(name="memberDetail"),
SecondaryTable(name="memberExtra"),
)
open class Member(
//...
@Column(table="memberDetail")
private var nickname: String?,
@Column(table="memberExtra")
private var favorites: MutableList<String>,
) {
//...
}@ElementCollection
여러개 데이터를 매핑하는 컬랙션 매핑하는 경우를 보자. 먼저 단순한 리스트형부터 보자.
@Entity
class Post (
//...
private var comments: MutableList<String>,
) {
//...
}단순 문자열 배열이다. JPA에서는 이 경우 한 컬럼에 저장한다. H2인 경우 charachter varying(255) array 타입으로 배열 형태의 데이터를 저장하는 데이터 타입으로 저장된다.
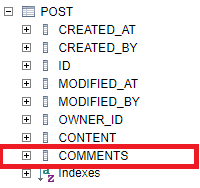
저장되는 데이터 개수가 작다면 크게 문제는 없지만, 매우 많아질 경우 분리하는게 좋다. 물론 이전에 1:N 관계로 분리할 수도 있지만 여기서는 좀더 쉽게 사용해보자. 해당 필드에 @ElementCollection 어노테이션을 추가하면 된다.
@Entity
class Post (
//...
@ElementCollection
private var comments: MutableList<String>,
) {
//...
}콜랙션 데이터를 저장할 새로운 테이블이 생성되고 Post 테이블과 1:N 관계가 생성된다. 생성되는 테이블 이름은 현재 엔티티 이름과 필드 이름으로 생성되고, 외래키는 엔티티 이름과 기본크 이름으로 생성된다.
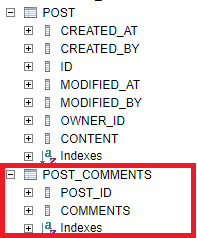
@ElementCollection 어노테이션에서 지원하는 속성은 다음과 같다.
- targetClass: 컬렉션에 데이터 타입, 별도로 설정하지 않아도 알아서 설정된다.
- fetch: 컬렉션 지연로딩(LAZY) 또는 즉시로딩(EAGER) 여부, 열거형 FetchType으로 설정(기본은 EAGER)
@CollectionTable 어노테이션
@ElementCollection 어노테이션과 같이 사용하여 컬랙션 매핑 설정을 한다. @ElementCollection 어노테이션에서 콜랙션용 테이블과 외래키 생성을 자동을 했지만, @CollectionTable에서 이런 부분을 설정할 수 있다. 지원하는 속성은 다음과 같다.
- name: 콜랙션 테이블 이름
- joinColumns: 엔티티의 기본 테이블을 참조하는 콜랙션 테이블의 외래키 설정, JoinColumn 어노테이션으로 설정(이전 JoinColumn 어노테이션 참조)
- foreignKey: jointColumns에 해당하는 컬럼에 대한 외래키 제약조건 생성 설정, ForeignKey 어노테이션으로 설정(아래 참조)
- indexes: 테이블을 위한 인덱스, Index 어노테이션을 설정(아래 참조)
- catalog: 데이터베이스 catalog 이름
- schema: 데이터베이스 schema 이름
- uniqueConstraints(DDL): 유니크 제약 조건
간단한 예를 보자.
@Entity
class Post (
//...
@ElementCollection
@CollectionTable(name="comments", joinColumns=ForeignKey(name="p_id"))
private var comments: MutableList<String>,
) {
//...
}이제 테이블 이름은 comments로 되고 그때 사용하는 외래키는 p_id가 된다.
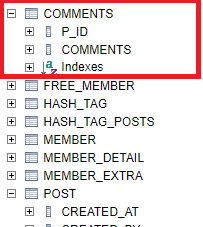
@MapKeyColumn 어노테이션
맵 형태의 콜랙션 데이터에 대한 매핑을 보자. 맵 형태의 데이터는 기본 매핑은 되지 않는다. @ElementCollection 어노테이션을 추가해야 가능하다. 그럴 경우 콜랙션용 테이블에는 키와 값이 저장가능한 컬럼이 추가된다. 예를 들어 다음과 같은 엔티티가 있다.
@Entity
class Post (
//...
@ElementCollection
private var recommends: MutableMap<String, String>,
) {
//...
}이럴 경우 생성되는 테이블은 다음과 같은 형태가 된다.
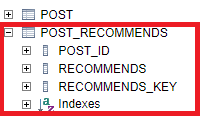
@MapKeyColumn 어노테이션을 사용해서 맵 형태 콜랙션을 테이블에 매핑하는 설정을 할수 있다. 이 어노테이션에서 제공하는 속성은 다음과 같다.
- name: 맵키 컬럼 이름
- table: 위의 컬럼이 포함된 테이블 이름
- insertable: insert시 포함 여부(읽기 전용시 false, 기본: true)
- updatable: update 허용 여부(읽기 전용시 false, 기본: true)
- length(DDL): String 문자열 길이 제약(기본: 255)
- unique(DDL): 유니크 제약 조건(단일 컬럼에 제약조건, 기본: false)
- nullable(DDL): null 허용 여부(false시 NOT NULL, 기본: true)
- columnDefinition(DDL): 컬럼 직접 설정
- precision, scale(DDL): BigDecimal타입의 전체자리수, 소수점 자리수 (기본: 0,0)
위의 속성은 @Column 어노테이션과 동일하다. 단지 name이 맵 객체의 키에 대응된다.
@Entity
class Post (
//...
@ElementCollection
@MapKeyColumn(name="recommend")
private var recommends: MutableMap<String, String>,
) {
//...
}생성되는 테이블은 다음과 같은 형태가 된다.
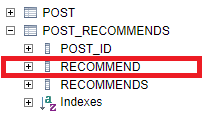
맵 객체의 키에 해당하는 컬럼이 변경되었다.
@PrimaryKeyJoinColumn 어노테이션
PrimaryKeyJoinColumn 어노테이션으로 다른 테이블과 조인하기 위한 외래키로 사용하는 기본키 컬럼 설정한다.
- name: 현재 테이블의 기본키 이름
- foreignKey: 컬럼 조인에 사용할 외래키 제약사항 설정, ForeignKey 어노테이션으로 설정(아래 참조)
- referencedColumnName: 조인할 기본키 컬럼 이름
- columnDefinition: 컬럼에 대해 DDL 생성시 사용할 쿼리
@ForeignKey 어노테이션
ForeignKey 어노테이션은 스키마 생성에서 사용되고 외래키 제약사항이나 공급자의 기본 외래키 정의를 재정의하거나 비활성화하는데 사용한다.
- foreignKeyDefinition: 외래키 제약 사항
- name: 외래키 제약 사항 이름
- value: 외래키 제약 사항 설정, 열거형 ConstraintMode로 설정(아래 참조)
열거형 ConstraintMode은 제약 사항 설정하는데 사용한다.
- CONSTRAINT: 제약 사항 적용
- NO_CONSTRAINT: 제약 사항 미적용
- PROVIDER_DEFAULT: 공급자 정의 기본 값
@Index 어노테이션
Index 어노테이션은 스키마 생성에 사용된다. 기본키는 자동 생성되므로 지정할 필요가 없지만, 인덱스 열 순서 지정에는 사용 할 수 있다.
- columnList: 인텍스에 포함되는 컬럼 이름 목록
- name: 인덱스 이름
- unique: 인덱스 고유성 여부
결론
지금까지 고급 매핑이라고 했지만, 기본적인 연관관계를 제외한 다른 관계에 대한 매핑을 다루었다. JPA가 어려운 점은 기존 매핑은 데이터 위주의 단순 매핑으로 어떻게든 처리했다면 지금은 클래스의 특성을 최대한 활용한 구조를 사용하면서 데이터베이스 매핑되는 구조까지 고려해야하는 어려움이 있다. 그냥 아무 생각없이 사용했다가 테이블 구조가 복잡해지면서 나중에 데이터베이스 관리가 더울 어려워지게 된다. 생각보다 제대로 사용하는데 시행착오와 시간이 오래 걸릴 듯 하다. 아무튼 확실한 것 부터 하나씩 사용하면서 확장하는게 좋다고 본다.
부족한 글이지만 여러분에게 도움이 되었으면 합니다. 모두 즐거운 코딩생활 되세요. ospace.
참고
[1] 최범균, JPA 프로그래밍 입문, 가메출판사, 2017
[2] 김영한, 자바 ORM 표준 JPA 프로그래밍, 에이콘, 2015
[3] JPA: Implementing Model Hierarchy - @MappedSuperclass vs. @Inheritance, https://stackoverflow.com/questions/9667703/jpa-implementing-model-hierarchy-mappedsuperclass-vs-inheritance
[4] Package javax.persistence, https://docs.jboss.org/hibernate/jpa/2.1/api/javax/persistence/package-summary.html
'3.구현 > Java or Kotlin' 카테고리의 다른 글
| [kotlin] JPA 7: Spring Boot에서 JPQL과 @Query (0) | 2024.04.29 |
|---|---|
| [kotlin] JPA 6: Spring Boot에서 Repository 활용 (2) | 2024.04.18 |
| [kotlin] JPA 4: Spring Boot에서 Entity 연관관계 (4) | 2024.04.11 |
| [kotlin] JPA 2: Spring Boot에서 Entity 매핑 기본 (0) | 2024.04.06 |
| [kotlin] JPA 1: Spring Boot에서 간단한 CRUD (2) | 2024.04.04 |


